Ediacaran
Fundamental research.
- 16xx-18xx: Coming up with the maths.
- 1920: Improving the maths.
- 1940: Conceptualizing neural nets. Research splits into two branches, NNs and ANNs. – Neural network - Wikipedia vs. Neural network (machine learning) - Wikipedia
- 1958: Invention of the perceptron, the first implemented artificial neural network.
- 1960: Markov algorithm - Wikipedia
- 1965: Hidden Markov model - Wikipedia
- 1966: Alexey Ivakhnenko is looking at Cybernetic Predicting Devices.
Cambrian
Designing, implementing, and toying around with all of that, deliberately using low memory and CPU power, and not using the Internet, because the system was designed to work in offline mode only.
Overview
- Backpropagation - Wikipedia
- Deep learning - Wikipedia
- https://datafloq.com/read/resurgence-of-artificial-intelligence-1983-2010/
1960-1980
- 1967: Alexey Ivakhnenko published the first general, working learning algorithm for supervised, deep, feedforward, multilayer perceptrons.
- 1967: Shun’ichi Amari published the first deep learning multilayer perceptron trained by stochastic gradient descent.
- 1972/1982: RNNs become adaptive and learning / capable of being trained.
1980-2000
- 1980: Kunihiko Fukushima proposed the Neocognitron, a hierarchical, multilayered artificial neural network. It started deep learning architectures for convolutional neural networks (CNNs) with convolutional layers and downsampling layers.
- 1986: Rina Dechter coined the term “deep learning”.
- 1986: Restricted Boltzmann machine (RBM), a generative stochastic artificial neural network that can learn a probability distribution over its set of inputs.
- 1988: Copycat (software) - Wikipedia
- 1988: Wei Zhang et al. applied the backpropagation algorithm to a convolutional neural network.
- 1991: Josef Hochreiter published »Untersuchungen zu dynamischen neuronalen Netzen«, one of the most important documents in the history of machine learning, according to his supervisor, Jürgen Schmidhuber.
- 1992: Jürgen Schmidhuber proposed an alternative to RNNs, which is now called a linear Transformer (deep learning architecture) - Wikipedia.
- 1993: Predictive modelling - Wikipedia
- 1995: Sepp Hochreiter and Jürgen Schmidhuber propose Long short-term memory (LSTM), which is an artificial neural network used in the fields of artificial intelligence and deep learning. LSTM overcomes the problem of numerical instability in training recurrent neural networks (RNNs) that prevents them from learning from long sequences (vanishing or exploding gradient). LSTM recurrent neural networks can learn “very deep learning” tasks with long credit assignment paths that require memories of events that happened thousands of discrete time steps before.
Carboniferous
Trying the same things with more memory, CPU power, and using the Internet, because, well, it made sense.
2000-2010
-
2006: LSTMs are been combined with connectionist temporal classification (CTC) in stacks of LSTM RNNs.
-
2006: Pre-training a many-layered feedforward neural network effectively one layer at a time, treating each layer in turn as an unsupervised restricted Boltzmann machine, then fine-tuning it using supervised backpropagation.
~2010bis
The deep learning revolution.
First production-grade applications
- Natural language processing (NLP): Speech and handwriting recognition, machine translation, etc.
- Image classification and object detection
- Bioinformatics: Drug discovery and toxicology.
Events
- 2009: Advances in hardware have driven renewed interest in deep learning. Nvidia was involved in what was called the “big bang” of deep learning, “as deep-learning neural networks were trained with Nvidia graphics processing units (GPUs).” That year, Andrew Ng determined that GPUs could increase the speed of deep-learning systems by about 100 times. In particular, GPUs are well-suited for the matrix/vector computations involved in machine learning. GPUs speed up training algorithms by orders of magnitude, reducing running times from weeks to days. Further, specialized hardware and algorithm optimizations can be used for efficient processing of deep learning models.
- 2014: Generative adversarial network - Wikipedia
- 2015: OpenAI was founded.
- 2015: Diffusion model - Wikipedia
- 2016: Google Translate changes its technology from statistical machine translation to neural machine translation.
2014-2017
The earliest “large” language models were built with recurrent architectures such as the long short-term memory (LSTM).
2017 Attention Is All You Need
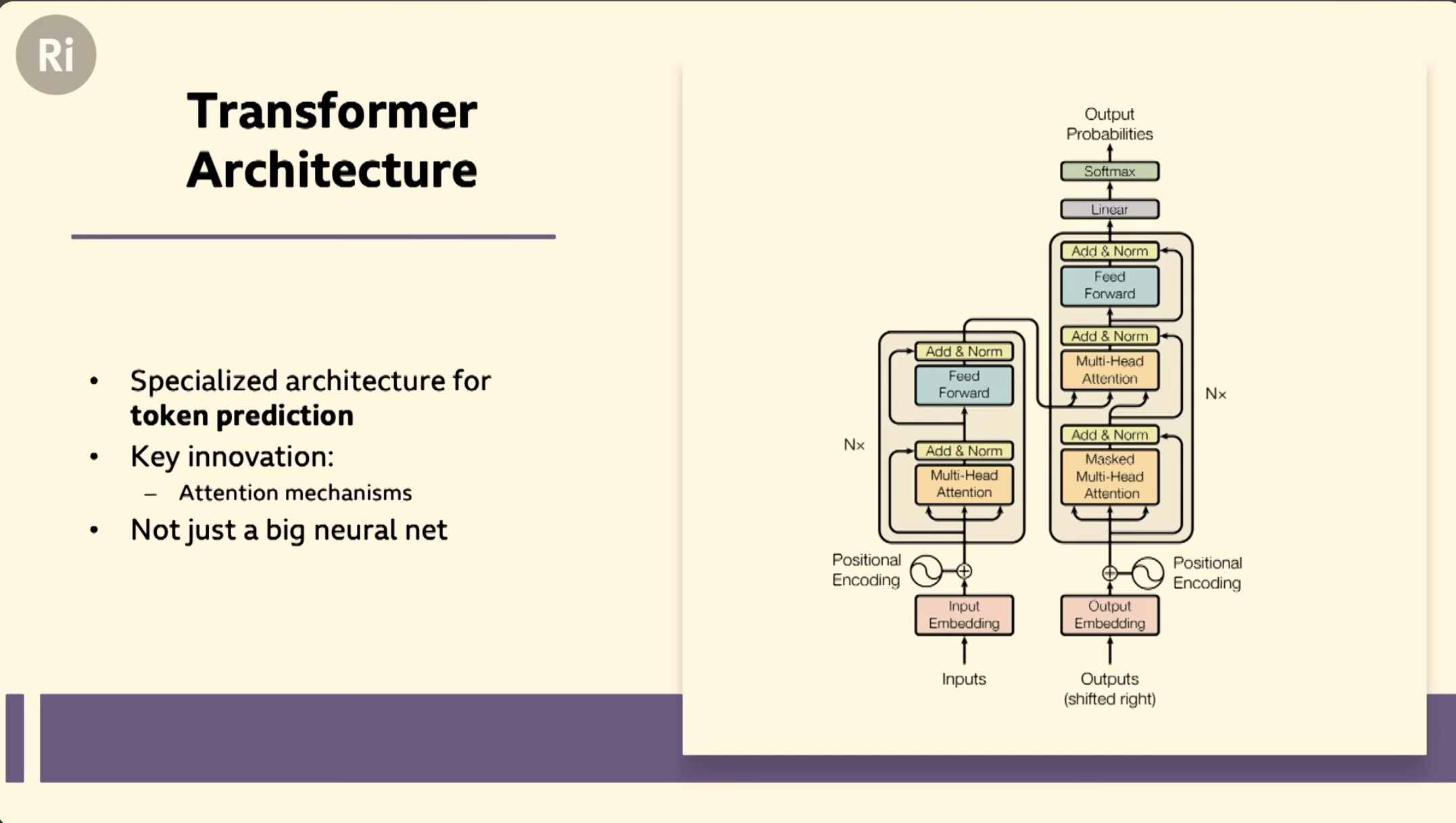
– [1706.03762] Attention Is All You Need
– https://youtu.be/b76gsOSkHB4?t=855
2018-
Todo: Ran out of fuel. Please pick up the torch.
Language models and word embeddings become large language models. LLMs can acquire an embodied knowledge about syntax, semantics and “ontology” inherent in human language corpora, but also inaccuracies and biases present in the corpora.
Image generation leads to Artificial intelligence visual art - Wikipedia, and beyond. Prompt engineering becomes a thing.
- 2018: Contemporary LLMs. The main architectures as of 2023, are of one of two types:
- 2018: GPT-1, Generative pre-trained transformer - Wikipedia
- 2019: GPT-2 - Wikipedia
2020
Unprecedented size. Just download and feed the whole WWW through Common Crawl and friends. OpenAI built a very advanced auto-complete.
– https://youtu.be/b76gsOSkHB4?t=1060
2021-
- 2021: DALL·E
- 2022: DALL·E 2
- 2022: Stable Diffusion - Wikipedia
- 2022: Midjourney - Wikipedia
- 2022: ChatGPT - Wikipedia
- 2023: GPT-4 - Wikipedia
https://invidious.fdn.fr/watch?v=PdE-waSx-d8